|
|
|
| "A fact is a simple statement that everyone believes. It is innocent unless found guilty.
A hypothesis is a novel suggestion that no one wants to believe. It is guilty until found
effective." --
Edward Teller |
|
| I work in the area of complex systems research,
bringing and developing tools from mathematics, equilibrium and non-equilibrium
statistical physics, nonlinear dynamics and chaos theory to bear on problems
in network science, neuroscience, biophysics, fluid dynamics, processes in
solids, social sciences and foundations of computing.
|
|
Recent papers
| •
J.S. Martinez Armas, K. Knoblauch, H. Kennedy and Z. Toroczkai.
"A principled approach to community detection in interareal cortical networks."
submitted (2024).
| doi: 10.1101/2024.08.07.606907 (biorxiv)
|
| •
P.L. Erdős, S.R. Kharel, T.R. Mezei, Z. Toroczkai.
"New results on graph matching from degree-preserving growth"
Mathematics 22(12), 3518 (2024).
| Featured, cover-page article
| doi: 10.3390/math12223518 (open access)
| arXiv: 2204.07423 [math.CO]
|
| •
D. Wolpert, J. Korbel, C.W. Lynn, F. Tasnim, et al., Z. Toroczkai and J. Paradiso.
"Is stochastic thermodynamics the key to understanding the energy costs of computation?"
PNAS USA 12(45), e2321112121 (2024).
| doi: 10.1073/pnas.2321112121 (open access)
| arXiv: 2311.17166 [cond-mat.stat-mech]
|
| •
Z. Toroczkai.
"Graph theory captures hard-core exclusion. (News and Views editorial)"
Nature Physics 20, 20 (2024).
| doi: 10.1038/s41567-023-02342-7
|
| •
P.L. Erdős, G. Harcos, S.R. Kharel, P. Maga, T.R. Mezei, Z. Toroczkai.
"The sequence of prime gaps is graphic."
Mathematische Annalen 388, 2195 (2024), 21 pgs.
| doi: 10.1016/j.cpc.2020.107469 (open access)
| arXiv: 2205.00580 [math.CO],[math.NT]
|
| •
F. Molnár, A.R. Ribeiro Gomes, Sz. Horvát, M. Ercsey-Ravasz, K. Knoblauch, H. Kennedy, Z. Toroczkai.
"Predictability of cortico-cortical connections in the mammalian brain."
Network Neuroscience, 8(1), 138 (2024).
| doi.org/10.1162/netn_a_00345 (open access)
|
| •
D.L. Barabási, G. Bianconi, E. Bullmore, et al., Z. Toroczkai, E.K. Towlson, et al., and György Buzsáki
"Neuroscience Needs Network Science"
Journal of Neuroscience, 43(34), 5989 (2024).
| doi: 10.1523/JNEUROSCI.1014-23.2023
| arXiv: 2305.06160 [q-bio.NC]
|
| •
O. Malik, M. Varga, A. Moussawi, D. Hunt, B. Szymanski, Z. Toroczkai, and G. Korniss.
"Diffusive Persistence on Disordered Lattices and Random Networks."
Physical Review E, 109, 024113 (2024).
| doi: 10.1103/PhysRevE.109.024113
| arXiv:2207.05878 [cond-mat.stat- mech]
|
| •
P.L. Erdős, S.R. Kharel, T.R. Mezei, Z. Toroczkai.
"Degree-preserving graph dynamics: a versatile process to construct random networks"
Journal of Complex Networks, 11(6), cnad46 (2023)
| doi: 10.1093/comnet/cnad046
| arXiv: 2111.11994 [math.CO]
|
| •
S.R. Kharel, T.R. Mezei, S. Chung, P.L. Erdős and Z. Toroczkai.
"Degree-preserving network growth"
Nature Physics 18(1), 100-106 (2022).
|
| •
Czabarka, L.A. Székely, Z. Toroczkai, S. Walker
"An algebraic Monte-Carlo algorithm for the Bipartite Partition Adjacency Matrix realization problem"
Algebraic Statistics 12(2), 1150124 (2021).
| arXiv:1708.08242 [math.CO]
|
| •
S. Dutta, A. Khanna, H. Paik, D. Schlom, A. Raychowdhury, Z. Toroczkai, S. Datta
"Ising Hamiltonian Solver using Stochastic Phase-Transition Nano-Oscillators"
Nature Electronics 4 502-512 (2021) .
| arXiv:2007.12331 [cond-mat.mes-hall]
|
| •
F. Molnár, S. R. Kharel, X. Hu, Z. Toroczkai
"Accelerating a continuous-time analog SAT solver using GPUs"
Computer Physics Communications, 256 107469 (2020)
| doi: 10.1016/j.cpc.2020.107469
|
| •
S. Dutta, A. Khanna, J. Gomez, K. Ni, Z. Toroczkai, S. Datta.
"Experimental Demonstration of Phase Transition
Nano-Oscillator Based Ising Machine."
2019 IEEE International Electron Devices Meeting (IEDM19), San Francisco, CA, USA, pp. 37.8.1-37.8.4 (2019)
| doi: 10.1109/IEDM19573.2019.8993460
|
| •
H. Yamashita, H. Suzuki, Z. Toroczkai and K. Aihara.
"Bounded Continuous-Time Satisfiability Solver"
Proceedings of the 2019 International Symposium on Nonlinear Theory and its Applications
(NOLTA2019) pp. 436-439 (2019).
|
| •
B. Molnár, F. Molnár, M. Varga, Z. Toroczkai, M. Ercsey-Ravasz.
"A continuous-time Max-SAT solver with high analog performance."
Nature Comm. 9 4864 (2018)
| arXiv:1801.06620 [cs.CC]
| doi: 10.1038/s41467-018-07327-2
|
| •
R. Gamanut, H. Kennedy, Z. Toroczkai, M. Ercsey-Ravasz, D.C. Van Essen, K. Knoblauch
and A. Burkhalter
"The Mouse Cortical Connectome, Characterized by an Ultra-Dense Cortical Graph, Maintains
Specificity by Distinct Connectivity Profiles"
Neuron 97, 698-715 (2018) | doi: 10.1016/j.neuron.2017.12.037
|
|
|
Selected publications
| • Sz. Horvát, É. Czabarka and Z. Toroczkai.
"Reducing Degeneracy in Maximum Entropy Models of Networks."
Phys. Rev. Lett., 114 158701 (2015)
| doi:10.1103/PhysRevLett.114.158701
| arXiv:1407.0991 [cond-mat.stat-mech]
|
| • Y. Ren, M. Ercsey-Ravasz, P. Wang, M. C. González and Z. Toroczkai.
"Predicting commuter flows in spatial networks using a radiation model
based on temporal ranges."
Nature Comm.
5, 5347 (2014)
| doi: 10.1038/ncomms6347
| arXiv:1410.4849 [physics.soc-ph]
|
| • N.T. Markov, M. Ercsey-Ravasz, D.C. Van Essen,
K. Knoblauch, Z. Toroczkai and H. Kennedy.
"Cortical high-density counter-stream architectures."
Science
342(6158), 1238406 (2013).
| Link to journal |
| doi: 10.1126/science.1238406
|
| • H. Kim, C.I. Del Genio, K.E. Bassler and Z. Toroczkai.
"Constructing and sampling directed graphs with given degree sequences."
New J. Phys.
14, 023012 (2012).
arxiv.org/1109.4590
|
| • M. Ercsey-Ravasz and Z. Toroczkai.
"The Chaos Within Sudoku."
Scientific Reports,
2, 725 (2012).
| doi:10.1038/srep00725
| arxiv.org: 1208.0370
|
| ♣ M. Ercsey-Ravasz and Z. Toroczkai.
"Optimization hardness as transient chaos in an analog approach to constraint satisfaction."
Nature Physics
7, 966-970 (2011). Cover-page article. | doi:10.1038/nphys2105
| arxiv.org: 1208.0526v1
|
| • S. Eubank, H. Guclu, V.S.A. Kumar, M. Marathe, A. Srinivasan, Z. Toroczkai, N. Wang.
"Modelling disease outbreaks in realistic urban social networks."
Nature
429(6988), 180 (2004).
|
| • M. Anghel, Z. Toroczkai, K.E. Bassler, G. Korniss
"Competition-driven Network Dynamics: Emergence of a Scale-free
Leadership Structure and Collective Efficiency."
Phys.Rev.Lett.
92 , 058701 (2004).
|
| • G. Korniss, M.A. Novotny, H. Guclu, Z. Toroczkai, P.A. Rikvold
"Suppressing Roughness of Virtual Times in Parallel Discrete-Event Simulations"
Science
299 , 677 (2003).
|
| • I.J. Benczik, Z. Toroczkai and T. Tél.
"Selective Sensitivity of Open Chaotic Flows on Inertial Tracer Advection:
Catching Particles with a Stick"
Phys.Rev.Lett.
89, 164501 (2002).
|
| • Z. Toroczkai
"Topological classification of the Horton-Strahler index on binary trees"
Phys.Rev.E
65, 016130 (2001).
| arxiv.org: cond-mat/0108448
|
| • G. Károlyi, Á. Péntek, I. Sheuring, T. Tél, and Z.
Toroczkai
"Chaotic flow: the physics of species coexistence"
Proc.Natl.Acad.Sci.USA
97(25), 13661-13665 (2000).
|
|
|
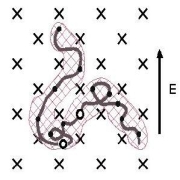
| For Fun: solving hard Sudokus with a continuous-time solver:
|
| Sudoku is an exact cover type of constraint satisfaction problem and
can be formulated as a Boolean Satisfiability problem (+1-in-9 SAT) and in turn transformed into
conjunctive normal form (CNF). Our analog and deterministic solver published in
♣ above
can be used to efficiently solve CNF SAT problems, and thus Sudoku as well. Here,
Mária Ercsey-Ravasz
with Erzsébet Regan have generated a
movie about
the "flow of thoughts" in some of the number fields (the right frame of the movie) by the solver,
when solving one of the hardest Sudoku puzzles on record (the puzzle is from Elser et.al.,
PNAS, 104(2) 418-423 (2007), Fig 5 of the Supporting Info). The movie can also be
downloaded in wmv format and in mp4
format. Also see: arxiv.org: 1208.0370
|
|
 |
|
|
Zoltán Toroczkai
Professor,
Physics Department,
Concurrent Professor,
Computer Science and Engineering,
University of Notre Dame


Erdős
nr: 2
|
| |
♣ BlueSky: @ztoro.bsky.social
|
| |
|
|

| |